
SQL Rank Functions – Quick Breakdown
Contents
Among the myriad functions SQL offers, specific functions such as RANK and DENSE_RANK stand out for their utility in data analysis and reporting tasks.
These functions empower users to make sense of data by enabling them to order and rank data points within a data set based on specific criteria.
In this tutorial, you will learn how to use the RANK and DENSE_RANK functions in MS SQL Server.
You will see some practical scenarios, best practices, and pitfalls to avoid when working with SQL rank functions.
You can also enroll in one of our SQL courses where you’ll learn about these functions and much more with the help of one of our experienced trainers.
Ranking In SQL
Ranking in SQL is a pivotal concept that enhances our ability to sort and analyse data within databases. This feature allows us to assign a unique or sequential order to rows in a result set based on one or more columns.
The ranking is crucial in scenarios where understanding the position or standing of a particular data point within a larger set is necessary.
For instance, it can help identify the top performers in a sales data set, the highest grades in an academic record, or the most popular products in inventory based on sales.
With RANK in SQL, you can transform raw data into actionable insights, facilitating informed decision-making and strategic planning.
Curious about how to use SQL If Statements? Have a look at our article about the topic.
RANK Function
The RANK function in SQL is a type of window function applied to a set of rows, assigning each row a rank within a partition of the result set. It comes in handy when you order items by a specific column, such as sales or scores, and determine their position within that order.
The syntax of the RANK function is as follows:
| SELECT column1, column2, RANK () OVER (ORDER BY column_name DESC/ASC) AS column alias FROM table |
A key feature of a RANK function in SQL is its ability to handle ties; if two rows have duplicate values in the ORDER BY column, they receive the same rank, and the subsequent rank number is skipped.
This makes the RANK function particularly useful in scenarios where precise ranking is essential, such as leaderboard creation, performance evaluation, or sales comparisons.
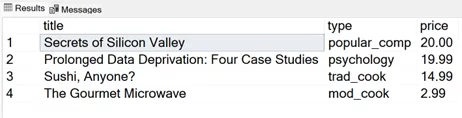
Let’s see a simple example. We will try to assign ranks to the book titles from the Microsoft pubs sample database in descending order of their prices. The most expensive book will have the rank of 1, and so on.
| USE pubs SELECT title, type, price, RANK () OVER (ORDER BY price DESC) AS price_rank FROM titles |
Output:
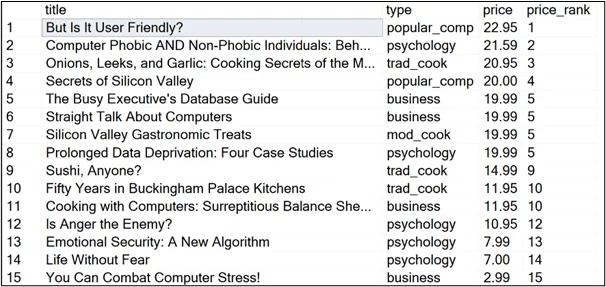
As you can see, the title prices from rows 5 to 8 are tied; all these titles are assigned a price rank of 5. The rank values from 6 to 8 are skipped, and the 9th row is assigned the rank of 9.
What if you do not want to skip any ranks in the case of a tie? This is where the DENSE_RANK function comes into play.
If you are considering applying for an SQL-related job, our article about SQL interview questions might come in handy.
DENSE_RANK Function
DENSE_RANK is similar to a RANK function in that both functions are applied across rows to allocate a rank to each row within a specific partition of the result set.
However, the DENSE_RANK function stands out by not skipping any ranks in the event of a tie. When multiple rows share the same value in the ordered column, each tied row is assigned the same rank, and the next rank continues sequentially without any gaps.
This characteristic of DENSE_RANK is particularly beneficial for applications requiring a continuous ranking sequence, such as inventory listings, academic standings, or any context where gaps in ranking could lead to confusion or misinterpretation.
The syntax of the DENSE_RANK function is very similar to the RANK function:
| SELECT column1, column2, DENSE_RANK () OVER (ORDER BY column_name DESC/ASC) AS column_alias FROM table |
To illustrate the difference between the RANK and DENSE_RANK functions, let’s try to rank book title prices using the DENSE_RANK function and the RANK function.
| SELECT title, type, price, RANK () OVER (ORDER BY price DESC) AS price_rank, DENSE_RANK () OVER (ORDER BY price DESC) AS dense_price_rank FROM titles |
Output:
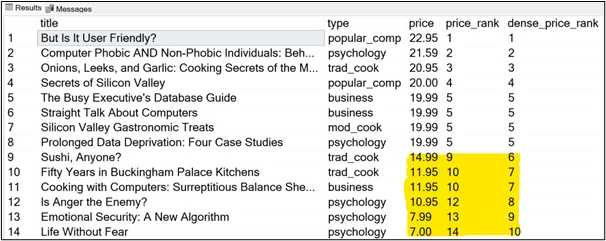
The above output shows that the DENSE_RANK function assigns the next rank in the sequence even if the previous ranks were tied.
Sometimes we need to perform calculations over multiple rows. Our article about SQL aggregate functions explains everything.
Practical Applications Of Ranking
RANK and DENSE_RANK functions have many practical applications. For example, you can use these functions to rank employees by their salaries within each department in a company, or you can also rank departments by the highest salary paid to an employee within a department. You can also get the salary of the nth highest paid employee overall or within different departments.
Let’s see some examples in the context of the Pubs database.
Using the RANK function, let’s first rank book titles by highest prices within each book type category. You can notice that we use the PARTITION BY clause in the following script. This clause is used within the OVER clause when you want to partition the data by column before applying a RANK function.
| SELECT title, type, price, RANK () OVER (PARTITION BY type ORDER BY price DESC) AS type_price_rank FROM titles; |
Output:
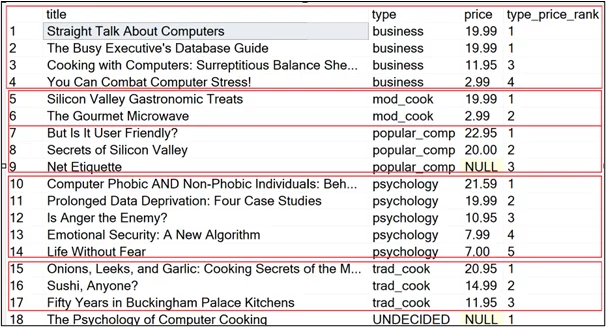
You can see price ranks for different types of book titles. To avoid skipping ranks in case of a tie, use the DENSE_RANK function in the above example.
You can also use an SQL rank function with aggregated functions such as MIN, MAX, AVG, etc. Let’s see another example of ranking book types by the average price of books within a book type category.
In the following query, we sort the book titles by the highest price and then group the records by type. Finally, we apply the DENSE_RANK function to the grouped data.
| SELECT type,
DENSE_RANK () OVER (ORDER BY AVG(price) DESC) AS price_rank FROM titles GROUP BY type; |
Output:
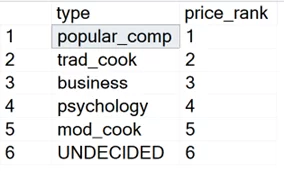
The above output shows that the popular_camp type books are the most expensive on average.
Filtering And Sorting With RANK
You can use the WHERE and ORDER BY clauses to filter and sort the data returned by the RANK functions further. To do so, you can first store the result of the RANK function in a Common Table Expression (CTE) and then apply to it the WHERE or ORDER BY clause.
Let’s see an example where we will first sort the book titles by their price, store the result in a CTE, and then filter the result to get the book title and price of the third most expensive book.
| WITH RankedTitles AS ( SELECT title, price, RANK() OVER (ORDER BY price DESC) AS price_rank FROM titles ) SELECT title, price FROM RankedTitles WHERE price_rank = 3; |
Output:

It is important to note that the CTE created with the RANK function may not contain the desired rank in case of a tie. In such cases, the WHERE clause will return an empty result.
For example, since we do not have the price rank 6 in the above CTE, the WHERE clause will return nothing for the following script:
| SELECT title, price FROM RankedTitles WHERE price_rank = 6; |
Output:
If unsure whether the CTE will contain your desired data, use a DENSE_RANK function.
Let’s see one more example: We will try to retrieve the 2nd most expensive book within each book type category, then sort the CTE result by price using the ORDER BY clause.
| WITH RankedTitles AS ( SELECT title, type, price, RANK() OVER (PARTITION BY type ORDER BY price DESC) AS price_rank FROM titles ) SELECT title, type, price FROM RankedTitles WHERE price_rank = 2 ORDER BY price DESC; |
Output:
Do you master the SQL update statement? If not, it’s time to read our article about this topic.
Best Practices & Common Pitfalls
Let’s now discuss some best practices and pitfalls while working with the SQL RANK functions.
Here are some best practices that you should adopt when using SQL Rank functions:
- Indexing for Performance: Ensure relevant columns used in the ORDER BY clause of the RANK or DENSE_RANK functions are indexed. This can significantly speed up the ranking process, especially in large data
- sets.
- Partitioning Wisely: Use the PARTITION BY clause judiciously. While it’s powerful for segmenting data into meaningful groups, excessive partitioning can lead to performance degradation. Aim for a balance between the granularity of the analysis and query efficiency.
- Avoiding Redundant Rankings: If multiple queries in the same session require similar rankings, consider using a Common Table Expression (CTE) or a temporary table to store the ranked data. This approach prevents the need to recalculate the ranks for each query.
- Selective Ranking: Only apply ranking functions to the required subset of data. Filtering data before ranking can reduce the computational load and improve query performance.
Following are some of the pitfalls to avoid when using RANK functions:
- Misunderstanding Ties: Remember that RANK will skip subsequent ranks after a tie, while DENSE_RANK will not. Choose the function that best suits your needs to avoid unexpected results in ranked data.
- Overlooking NULL Values: SQL ranking functions consider NULL values during ranking, which might lead to unexpected outcomes. Ensure data is cleaned or transformed as necessary before applying ranking functions.
- Ignoring Query Cost: Complex ranking over large data sets can be resource-intensive. Monitor and optimise query performance by examining execution plans, especially for queries involving multiple ranking functions or large partitions.
- Neglecting Data Skew: In data sets with skewed distributions (e.g., a few partitions having significantly more data than others), ranking functions might perform inconsistently across partitions. Test and optimise for such scenarios to ensure consistent performance.
Conclusion
SQL’s rank functions are indispensable tools for any data enthusiast looking to dive deep into data analysis and reporting. Their ability to sort and rank data efficiently makes them crucial for various scenarios, from sales leaderboards to academic standings.
We encourage you to experiment with RANK and DENSE_RANK across different data sets and contexts. As you become more comfortable with these ranking functions, challenge yourself to explore other SQL features that can complement and enhance your data manipulation capabilities.
Would you like to learn more about SQL? Try these Top 3 SQL learning apps.

- Facebook: https://www.facebook.com/profile.php?id=100066814899655
- X (Twitter): https://twitter.com/AcuityTraining
- LinkedIn: https://www.linkedin.com/company/acuity-training/